Introduction
Initially introduced with the now-famous Attention is all you need1, the Transformer has dominated the field of Natural Language Processing (NLP) for years. Particularly worth noting is the effort gone into scaling up Transformer-based models, such as BERT2, MegatronLM3, T54, and the various GPTs (GPT5, GPT-26 and GPT-37), due to their favourable scaling characteristics8,9.
The success of transformers in NLP has not gone unnoticed in other fields, where they have been responsible for significant breakthroughs such as AlphaFold 2 in the field of protein folding.
Important works adapting transformers (and self-attention) to vision include Attention Augmented Convolutional Networks10, Stand-Alone Self-Attention models11 (SASA models), DETR12, Visual Transformers13 and LambdaNetworks14; as well as Image Transformers15 and Axial Transformers16 in the generative domain.
For an in-depth introduction to these works, we recommend two recent reviews: A Survey in Visual Transformers17 and Transformers in Vision: A Survey18.
Overview
This blog post aims to summarize recent research in applying transformers and self-attention to vision, with a focus on (but scope not limited to) image classification. While by no means exhaustive, it can hopefully represent a starting point for a more in-depth dive into the literature.
We first introduce the Vision Transformer, a simple yet powerful architecture that has had a significant influence on recent research due to its performance in large data regimes. We then continue with the many works studying how to achieve similar high performance using transformers (and self-attention) when data is not as plentiful. Finally, we discuss papers studying the robustness of these models to perturbations as well as their performance in self-supervised, medical and video tasks.
Figures are taken from their respective papers unless the source is explicitly provided in the caption.
Before we begin, it is worth noting that familiarity with transformers and self-attention is recommended; great resources include Jay Alammar’s Illustrated Transformer and Peter Bloem’s Transformers from scratch. For high-quality implementations of many models discussed in this post, check out Ross Wightman’s PyTorch Image Models as well as Phil Wang’s work.
Vision Transformers for Image Recognition
An image is worth 16x16 words: the Vision Transformer
First introduced in An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale19, Vision Transformers (ViTs) have taken computer vision by storm, leading to hundreds of citations in the span of a few months. The paper’s main goal was to show that a vanilla Transformer, once adapted to deal with data from the visual domain, could compete with some of the most performant convolutional neural networks (CNNs) developed up to that point.
The Vision Transformer architecture is conceptually simple: divide the image into patches, flatten and project them into a \(D\)-dimensional embedding space obtaining the so-called patch embeddings, add positional embeddings (a set of learnable vectors allowing the model to retain positional information) and concatenate a (learnable) class token, then let the Transformer encoder do its magic. Finally, a classification head is applied to the class token to obtain the model’s logits.
](ViT.gif)
Figure 1: A Vision Transformer classifying an image. Source.
The model’s performance was acceptable when trained on ImageNet (\(1\)M images), great when pre-trained on ImageNet-21k (\(14\)M images), and state-of-the-art when pre-trained on Google’s internal JFT-300M dataset (\(300\)M images).
The striking performance improvement was due to the reduced inductive bias that characterizes Vision Transformers. By making fewer assumptions about the data, Vision Transformers could better adapt themselves to the given task. However, this ability came at a cost – when the sample size was too small (such as in the ImageNet case), the models overfit, resulting in degraded performance.
The goal for many follow-up papers would be that of matching (and surpassing) the performance of the best convolutional models in the “small” data regime – ImageNet (which is after all over a million images) and below.
Stronger data augmentation allows more efficient learning
Training data-efficient image transformers & distillation through attention20 was the first paper to show that models based on ViTs could be competitive on ImageNet without access to additional data.
Two main contributions characterize the paper:
- A novel training recipe (referred to below as the DeiT recipe), characterized by more substantial data augmentation and stochastic depth21. These changes introduce additional regularization limiting ViT’s tendency to overfit in the small data regime, thus boosting its performance. The authors recommend the use of Rand-Augment22, Mixup23, CutMix24, and Random Erasing25; they also recommend not to use DropOut26.
- Hard-label distillation. In this approach, an additional learnable token, called the distillation token, is concatenated to the patch embeddings. The model is then trained with the loss function \[\mathcal{L}_{hardDistill}=\frac{1}{2}\mathcal{L}_{CE}(\sigma(Z_{cls}), y_{true}) + \frac{1}{2}\mathcal{L}_{CE}(\sigma(Z_{distill}), y_{teacher})\] where \(\mathcal{L}_{CE}\) is the cross-entropy loss function, \(\sigma\) is the softmax function, \(Z_{cls}\) and \(Z_{distill}\) are the student model’s logits derived respectively from the class and distillation tokens, and \(y_{true}\) and \(y_{teacher}\) are respectively the true and the teacher’s hard labels. This distillation technique allows the model to learn even when the combination of multiple strong data augmentations causes the provided label to be imprecise, as the teacher network will produce the most probable label. Interestingly, the authors found CNNs to be better teacher networks than other Vision Transformers.
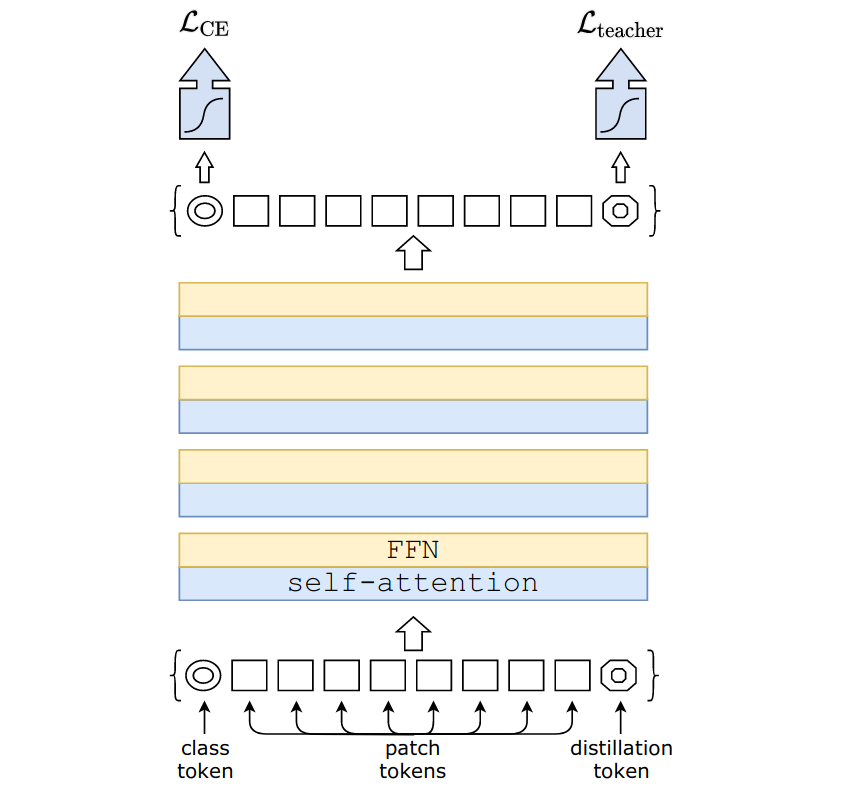
Figure 2: The Data efficient image Transformer hard-label distillation procedure.
The resulting models, called Data efficient image Transformers (DeiTs), were competitive with EfficientNet on the accuracy/step time trade-off, proving that ViT-based models could compete with highly performant CNNs even in the ImageNet data regime. It is however worth noting that DeiTs performed much worse than EfficientNets27 in terms of accuracy/parameters and accuracy/FLOPs.
Incorporating relative Self-Attention in ResNet design
Bottleneck Transformers for Visual Recognition28 investigated a family of hybrid convolution and attention models obtained by incorporating Multi-Head Self-Attention (MHSA) in ResNet designs. In particular, the authors showed that by simply replacing the \(3\times 3\) convolutions with relative position MHSA layers in the bottleneck blocks of the last stage of a ResNet, it was possible to obtain an improvement over several baselines.
Once additional bells-and-whistles were added, such as Squeeze-and-Excite layers29 and SiLU non-linearities30, the models (that the authors call Bottleneck Transformer Networks or BoTNets) demonstrated favorable scaling, outperforming EfficientNets in the accuracy/step-time trade-off beyond 83% top-1 accuracy. The worse performance of small BoTNet models could be due to the fact that the authors do not employ the DeiT training recipe to combat overfitting.
Further, the use of ResNet blocks in the initial stages to efficiently learn lower resolution feature maps allowed the models to perform well in both instance segmentation and object detection tasks, where high-resolution images are typical.
Conditional Positional Encodings
Conditional Positional Encodings for Vision Transformers31 studied alternatives to the positional embeddings and class token used in ViTs. In particular, the paper proposes the use of Positional Encodings Generators (PEGs), a module that produces positional encodings dynamically, and the use of global average pooling as an alternative to the (non-translation-invariant) class token.
PEGs reshape the flattened input sequence to 2D, apply a series of convolutional layers (the authors use depthwise separable convolutions) with zero-padding, and flatten the result. Positional information is thus introduced by the presence of zero-padding, unlike in ViTs, where 1D learnable positional embeddings are used. The method has two main advantages:
- The model is now translation invariant.
- The model can now be used as-is on higher resolutions, unlike normal ViTs that require rescaling of the positional embeddings before fine-tuning.
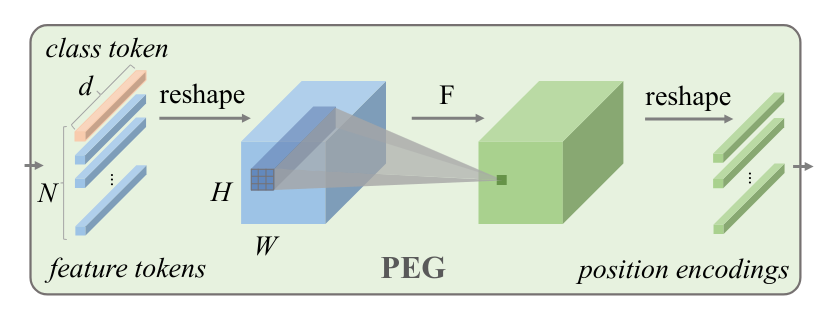
Figure 3: The Positional Encoding Generator (PEG) module architecture.
The resulting models, called Conditional Positional Encoding Vision Transformers (CPVTs), are trained with the DeiT recipe and obtain a small boost in performance (particularly when tested on higher resolution images without fine-tuning).
Modeling the local patch structure
Transformer in Transformer32 (TNT) studied the importance of intra-patch structure by introducing an additional transformer block, dedicated to pixel embeddings, inside the transformer blocks used in ViT.
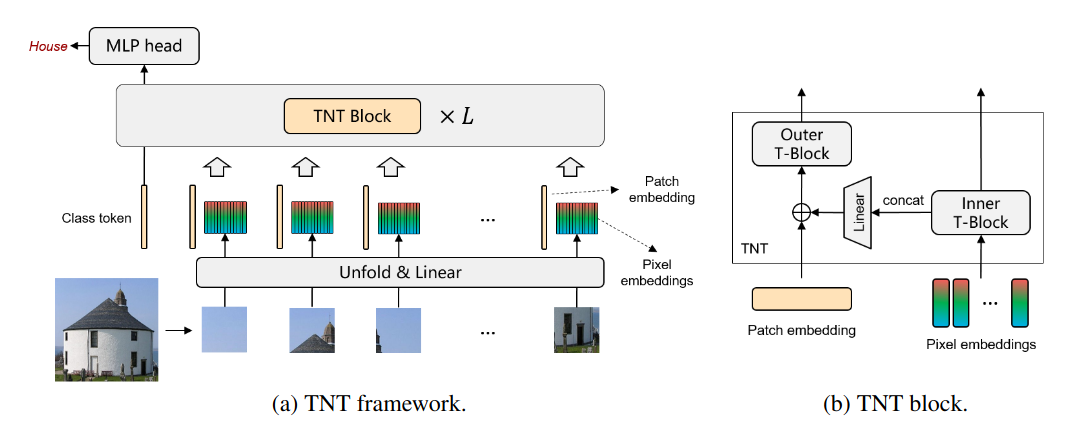
Figure 4: The Transformer in Transformer (TNT) architecture.
The output of the inner transformer block is both sent as-is to the next layer and adapted for use in the outer transformer block which can now take into account both inter-patch relationships (like ViT does) and intra-patch structure. The authors also introduced a separate set of positional embeddings, added to the pixel embeddings before entering the encoder.
The models, trained with the DeiT recipe, outperformed both ViTs and DeiTs on ImageNet, achieving higher parameter and FLOP efficiency, although not quite as high as EfficientNet’s.
Deeper and deeper with Vision Transformers
DeepViT: Towards Deeper Vision Transformer33 investigated how the performance of ViTs changed with increasing depth. After 24 transformer blocks, the authors discovered that adding additional blocks did not lead to improved performance, as both the feature maps and the attention matrices end up being remarkably similar to each other, a problem they name Attention Collapse.
To solve this issue, the authors proposed a simple variant of self-attention that they call Re-Attention, characterized by a learnable transformation matrix \(\Theta \in R^{H \times H}\) (where \(H\) is the number of attention heads) applied directly after the softmax. This matrix (which is shared throughout the network but can also be layer-specific) allows the model to establish cross-head communication, diminishing inter-layer feature map similarity.
The authors also reported positive results following an approach similar to the one proposed in LazyFormer34: reusing the attention matrix for the last half of the network caused no degradation in performance.
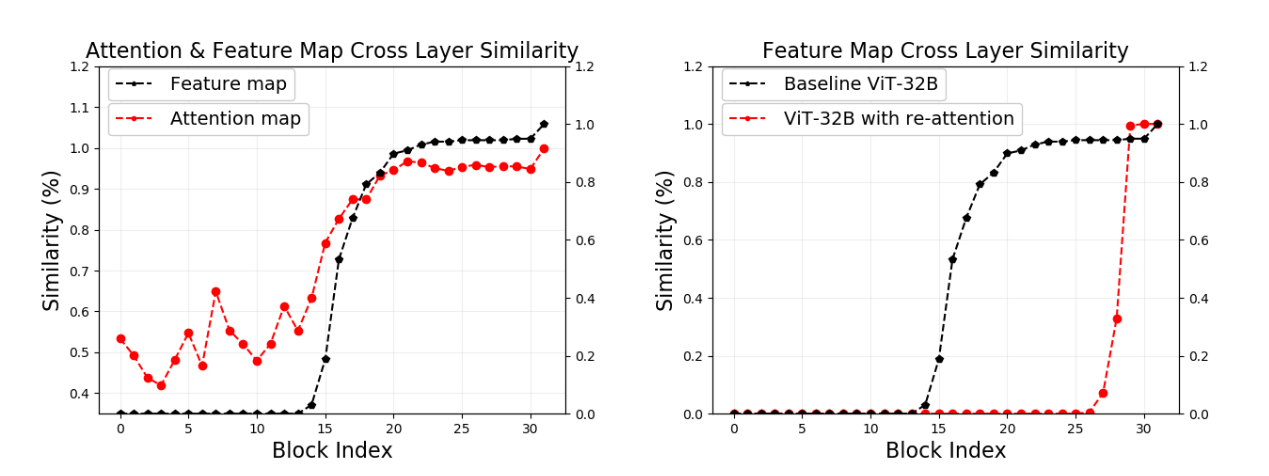
Figure 5: Attention and feature map cross layer similarity (left); ViT and DeepViT comparison (right).
The resulting models, called Deep Vision Transformers (DeepViTs), are characterized by better performance as depth increases.
Going deeper with Image Transformers35 identified two main issues in DeiT models: the lack of performance improvement (and even performance degradation) at increased network depth and the double objective that characterizes the transformer encoder, which has to model both inter-patch relationships as well as that between the class token and the patch embeddings. To demonstrate the latter, the authors show that a DeiT where the class token is inserted later on in the network outperforms a normal DeiT.
Two main contributions characterize the paper:
- LayerScale, a novel normalization strategy applied to residual branches.
- Class-attention layers, a layer dedicated to the efficient extraction of information relevant to the classification task from the processed patch embeddings.
LayerScale is characterized by a layer-specific set of learnable diagonal matrices, whose diagonal values are initialized to a small \(\epsilon\), applied to the output of every residual branch. It is conceptually similar to methods like FixUp36 and SkipInit37 but provides the model with more freedom since it is per-channel (unlike other methods that only use a single scalar).
As mentioned before, Class-attention layers allow efficient extraction of information from processed patch embeddings. The authors find it a better alternative than the simple late-stage insertion of the class token and global average pooling, achieving the same accuracy with lower computational costs.
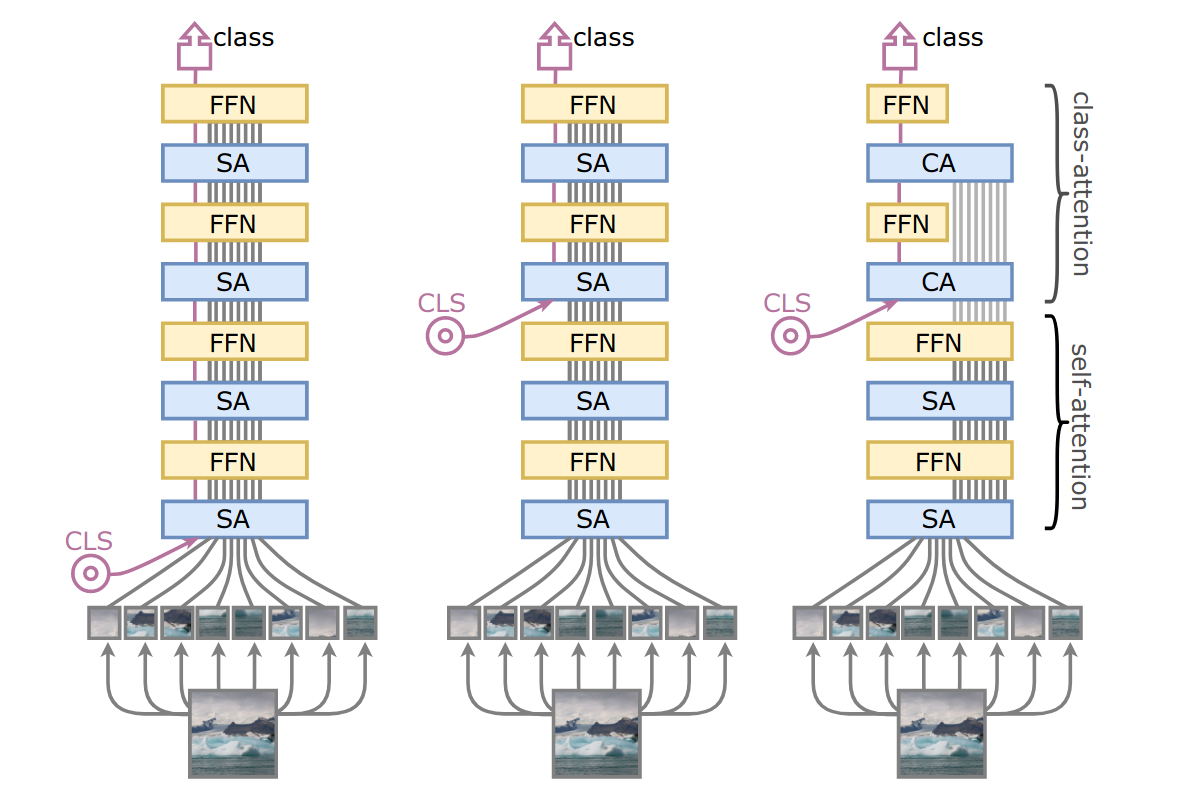
Figure 6: ViT (left), late class token ViT (center) and CaiT (right).
The authors also proposed the use of additional bells and whistles, such as Talking Heads Attention38.
The resulting models, called Class-attention image Transformers (CaiTs), achieved notable performance on the ImageNet benchmark. CaiTs even outperform the recent NFNets39 in both the accuracy/parameters trade-off and the accuracy/FLOPs trade-off when using both the DeiT training recipe as well as the DeiT distillation technique.
Convolutional insights
ConViT: Improving Vision Transformers with Soft Convolutional Inductive Biases40 investigated the exciting possibility of initializing self-attention blocks with soft convolutional biases. Basing their work on studies regarding the theoretical relationship between self-attention and convolutional layers41, the authors introduced Gated Positional Self-Attention (GPSA), a variant of self-attention which is characterized by the possibility of being initialized with a locality bias.
More precisely, the initialization of a GPSA block is parameterized by a head-specific center of attention (the position to which the head pays most attention to, given the query patch) and a locality strength (which determines how focused every head is around its center of attention). GPSA blocks also employ a gating mechanism to better balance content and positional information. By appropriately setting the centers of attention and the locality strength of GPSA blocks, the model can compete with CNNs in the low data regime and at the same time enjoy ViT-like expressive power in large data regimes.
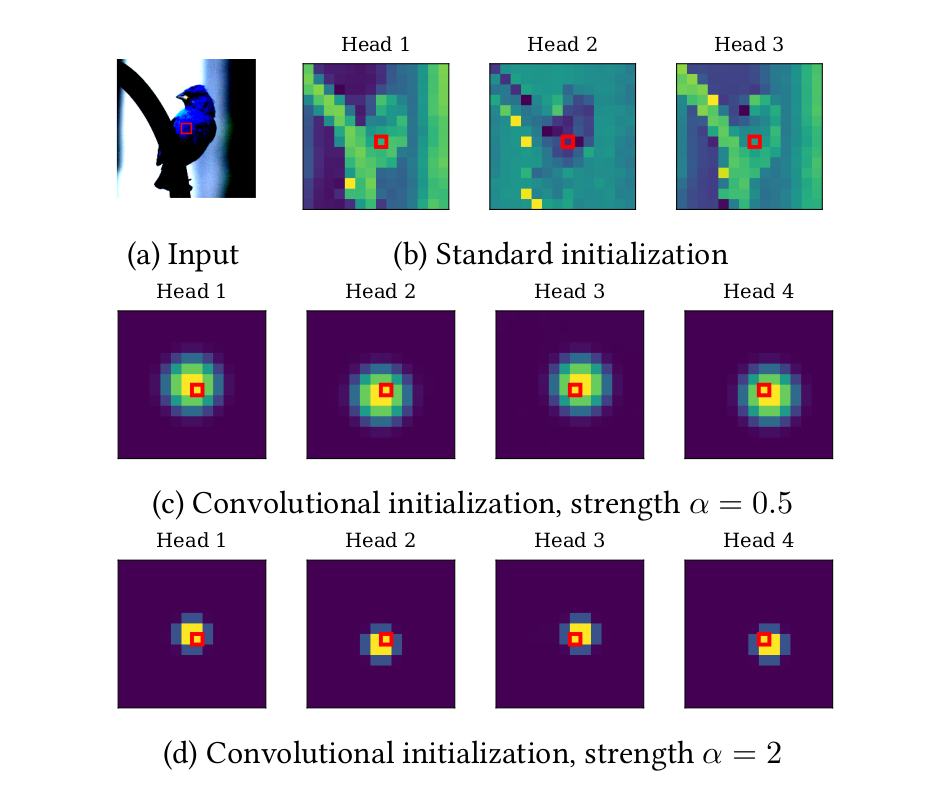
Figure 7: Input image (top left), attention maps of an untrained SA block (top right) and GPSA blocks (center and bottom).
The authors demonstrated the effectiveness of this elegant approach through an empirical study comparing DeiTs to the resulting models, which they named Convolutional Vision Transformers (ConViTs): on ImageNet ConViTs enjoy progressively superior performance as the sample size is diminished while retaining DeiT-like performance at full sample size.
Two more papers exploring the application of convolutional insights to Vision Transformers are Incorporating Convolution Designs into Visual Transformers42 and LocalViT: Bringing Locality to Vision Transformers43.
The first paper has three main contributions:
- The Image-to-Tokens (I2T) stem, substituting ViT’s convolutional stem and characterized by the addition of a max-pooling operation followed by batch normalization.
- The Locally enhanced Feedforward block, substituting ViT’s feedforward block and characterized by the use of depthwise convolutions and batch normalization.
- The Layer-wise Class-Token Attention, which is applied at the end of the network and attends unidirectionally to all class tokens throughout the network.
The authors adopted the DeiT training recipe; their models, called Convolution-enhanced image Transformers (CeiTs), obtained superior results against both same-size DeiT models and same-size distilled DeiT models.
The second paper also studied the application of depth-wise convolutions in the feedforward networks while ablating the use of different activation functions and the application of Squeeze-and-Excite layers.
The authors applied this approach to several models, obtaining favorable results.
The importance of Hierarchy
Several papers have studied the application of a hierarchical structure to Vision Transformers.
Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet44 introduced the Token-to-Token module (T2T), a module that reshapes the input sequence to a 2D structure, applies a soft split (allowing overlapping patches), and flattens the resulting patches. By adjusting the patch size used in the module, the length of the token sequences diminishes progressively throughout the network.
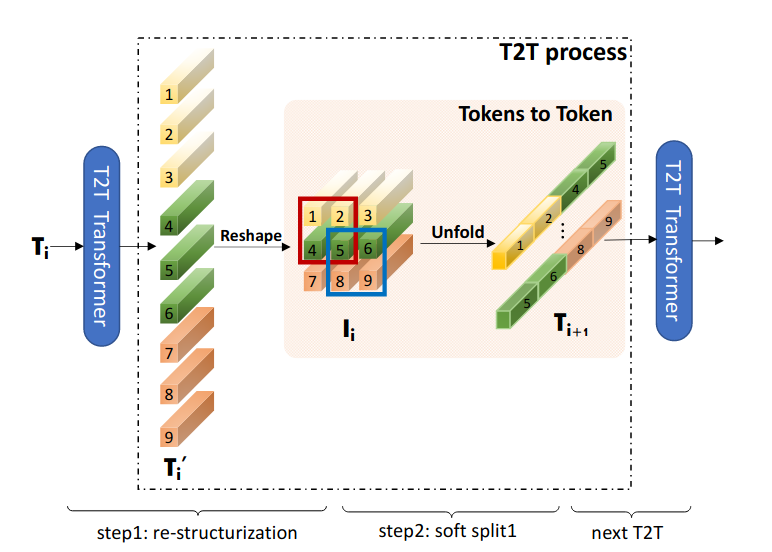
Figure 8: The Token-to-Token module architecture.
The authors obtained favorable results, with performance comparable to that of MobileNets45.
Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions46 introduced a variant of Self-Attention called spatial-reduction attention (SRA), characterized by spatial reduction of both keys and values. By applying SRA at the end of several stages, the spatial dimensions of the feature map slowly decrease throughout the model. The resulting models, called Pyramid Vision Transformers (PVTs), can deal with a variety of tasks, including dense prediction, object detection, and semantic segmentation, where high-resolution images are typical.
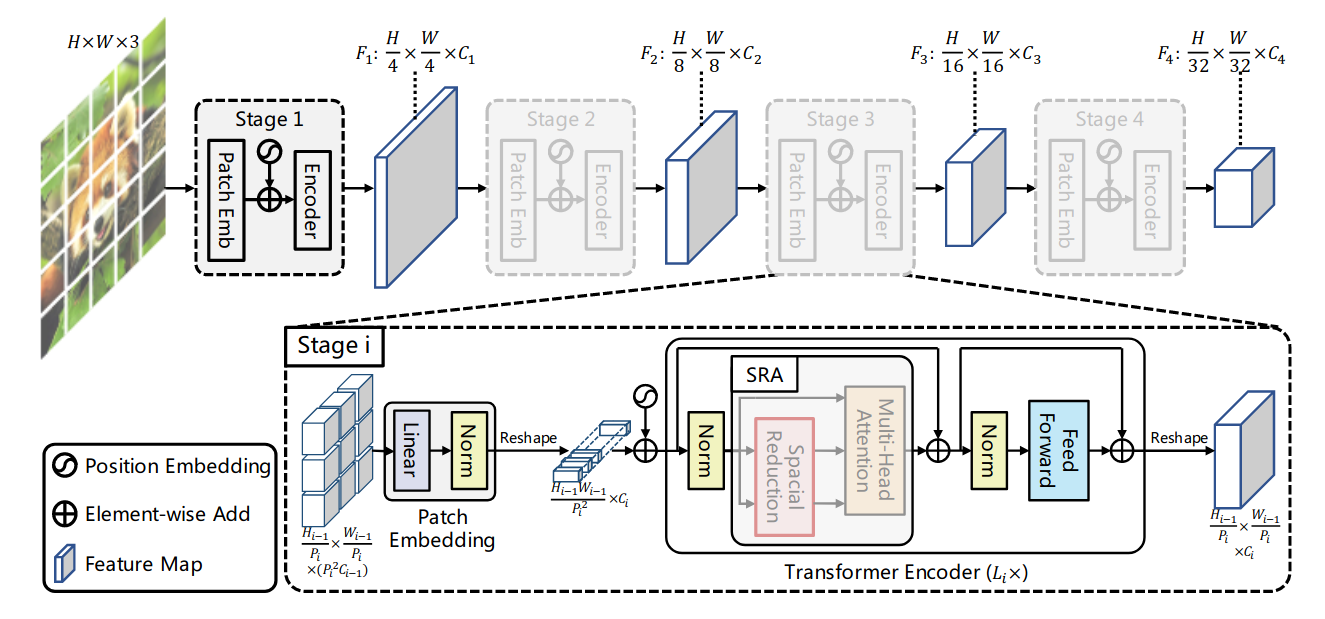
Figure 9: The Pyramid Vision Transformer.
Scalable Visual Transformers with Hierarchical Pooling47 explored the use of max-pooling to diminish the sequence length progressively. The authors also replaced the class token used in ViT with a final global average pooling layer. The resulting models, called Hierarchical Vision Transformers (HVTs), are trained with the DeiT recipe and scaled up (in the embedding dimension and number of heads) to have a comparable computational cost to DeiTs, achieving gains in the low (sub \(5\)) GFLOPs regime.
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows48 suggested a different route: use local self-attention inside (non-overlapping, local) windows, allow cross-window communication through so-called shifted window partitioning, and produce a hierarchical representation by progressively merging the windows themselves.
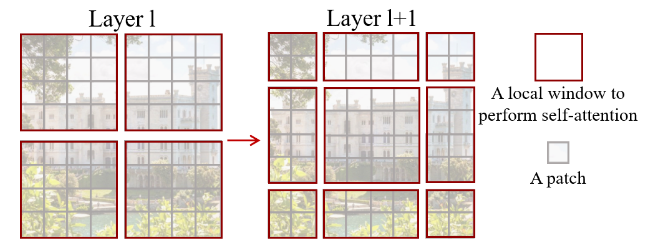
Figure 10: The Swin Transformer shifted window partitioning procedure.
In the last stage of the network, all local windows have been merged, resulting in blocks effectively using global self-attention on a feature map whose spatial dimensions have been significantly decreased. It’s worth noting that this approach scales linearly with image size.
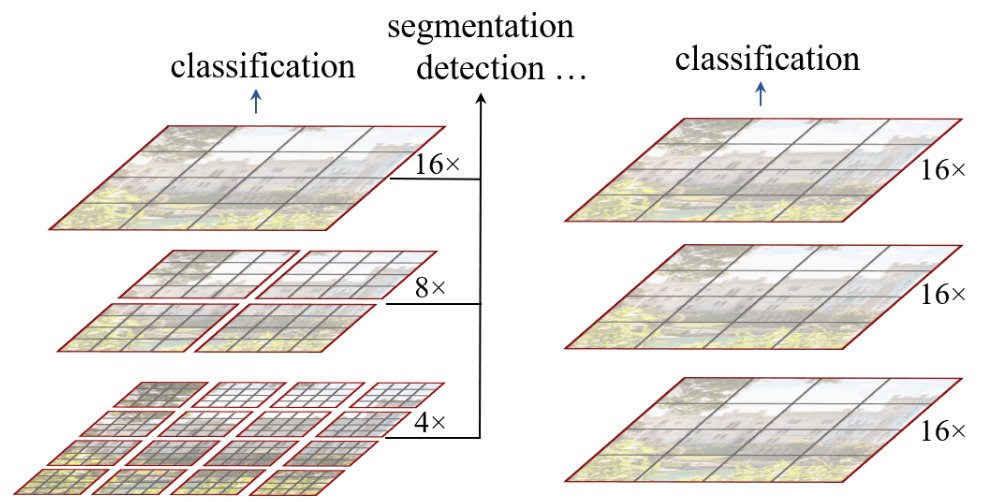
Figure 11: Swin Transformer (left) and ViT (right). Attention is applied on patches (black) inside windows (red).
The authors also reported positive results applying T5-style relative positional bias in attention blocks and obtained promising results on both ImageNet and ImageNet-21k, as well as in object detection and semantic segmentation tasks.
Rethinking Spatial Dimensions of Vision Transformers49 introduced a novel pooling layer, characterized by a depthwise convolution (for patch embeddings) and a fully connected layer (for the class token). This simple change allowed the models, named Pooling-based Vision Transformers (PiTs), to outperform vanilla Vision Transformers in the ImageNet data regime.
LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference50 studied a hybrid architecture characterized by a longer convolutional stem and shrinking attention blocks that progressively diminish the spatial dimensions of the feature maps throughout the network. The authors also proposed the use of global average pooling instead of the class token, the injection of positional information through attention bias, and the addition of a GELU activation51 in the attention block.
The authors named the models LeViTs, trained them using both the DeiT training recipe and the DeiT distillation procedure, and showed that the networks are capable of high-speed inference, outperforming EfficientNets and DeiTs in the accuracy/step-time trade-off, on both GPU and CPU.
Multi-Scale features and Cross-Attention
CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification52 proposed the use of multi-scale features by adapting the Vision Transformer to have two branches:
- A large (or primary) one characterized by large patch size, deep transformer encoder, and wide embedding dimension.
- A small (or complementary) one characterized by smaller patch size, shallower encoder, and narrower embedding dimension.
The branches employ two separate class tokens. Late in the network (after a separate set of positional embeddings is added), cross-branch communication is established through the use of Cross-Attention Fusion blocks.
In particular, inside cross-attention fusion blocks, class tokens are concatenated to the patch embeddings of the other branch and processed by attention before being returned to their respective branch.
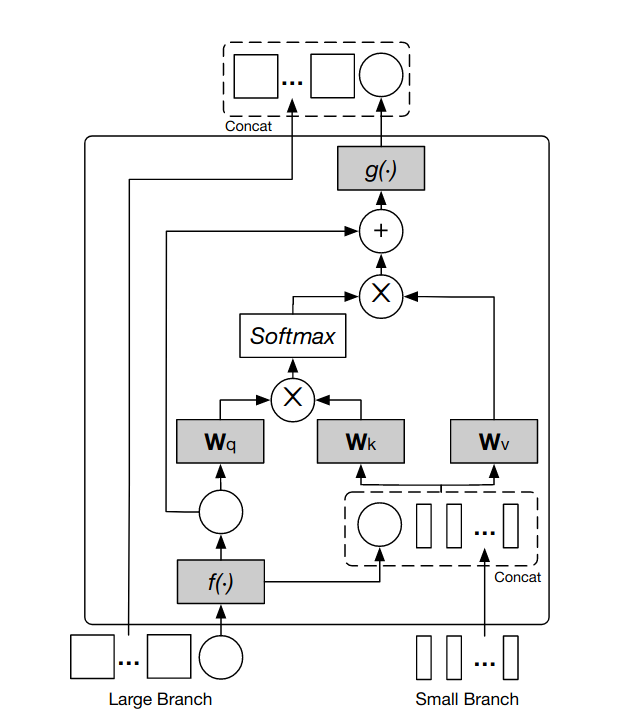
Figure 12: The Cross-Attention fusion layer for the large branch.
The output of MLP heads based on the large and small branches tokens is then added together to generate the model’s logits.
The resulting models, which the authors named CrossViTs, are trained with the DeiT recipe and enjoy significant performance boosts, achieving better performance than DeiTs twice as large and twice as computationally expensive.
Integrating convolutions in attention
CvT: Introducing Convolutions to Vision Transformers53 can be seen as a complementary approach to Bottleneck Transformers, where instead of using multi-head self-attention inside of a CNN’s final blocks, convolutions (in this case, depthwise separable ones54) are used inside a Vision Transformer’s self-attention blocks. More precisely, Convolutional vision Transformers (CvTs, whose full-name conflicts with ConViTs) are characterized by two main features:
- The Convolutional Token Embedding, a module characterized by a strided convolution and inserted at the beginning of every stage.
- The Convolutional Projection(s) in the attention blocks. These projections, implemented through depthwise separable convolutions, allow queries, keys, and values to be influenced by neighboring tokens. Further, larger strides for keys and values diminish the tokens spatial dimensions, decreasing the associated parameters count and computational cost.
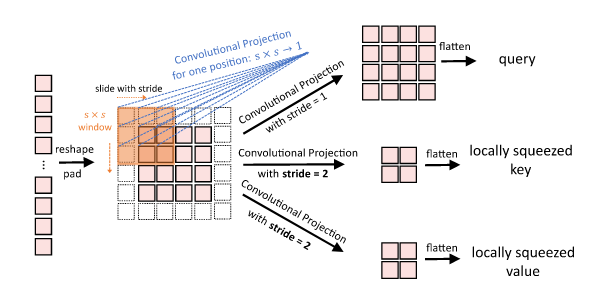
Figure 13: The (strided) Convolutional Projections.
These two features allow the model to progressively reduce the tokens feature and spatial dimensions, allowing CvTs to adopt a hierarchical multi-stage architecture.
It’s worth noting that CvTs do not employ positional embeddings since positional information is retained through the use of convolutions both in the embedding layers as well as in the attention blocks.
The authors adopted the original ViT training recipe and achieved competitive performance when training CvTs on ImageNet. The largest model presented (CvT-W24), once pre-trained on ImageNet-21k, obtained a stunning \(87.7\%\) top-1 accuracy, outperforming BiT-L (an ensemble of CNNs pre-trained on \(20\) times more data) with a fraction of parameters and compute.
Multi-Scale Vision Longformer: A New Vision Transformer for High-Resolution Image Encoding55 introduced a 2D version of Longformer56, which the authors call Vision Longformer. Conceptually, it is characterized by two different sets of tokens: a set of global tokens, allowed to attend to all tokens, and local tokens, only allowed to attend to global tokens and tokens spatially close to them.
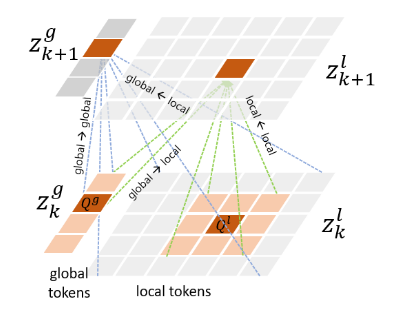
Figure 14: Global and local tokens in Multi-Scale Vision Longformers.
It’s worth noting that, at least in vision-only tasks, global tokens are discarded at the end of every attention block (while local tokens are reshaped and passed to the next one), since they have at that point already fulfilled their role of allowing efficient communication between spatially distant tokens.
The authors adopted DeiT-style training and achieved impressive parameter and FLOP efficiency.
Haloing and Strided local Self-Attention
Scaling Local Self-Attention for Parameter Efficient Visual Backbones57 builds on top of SASA models, by developing a local self-attention-only family of models made more efficient by the newly introduced haloing operation.
More precisely, the authors introduced a novel strategy called Blocked Self-Attention: input is first divided into blocks (which will be used as queries), and neighboring pixels are banded together and padded, in an operation denominated haloing, to generate keys and values. Finally, attention is applied.
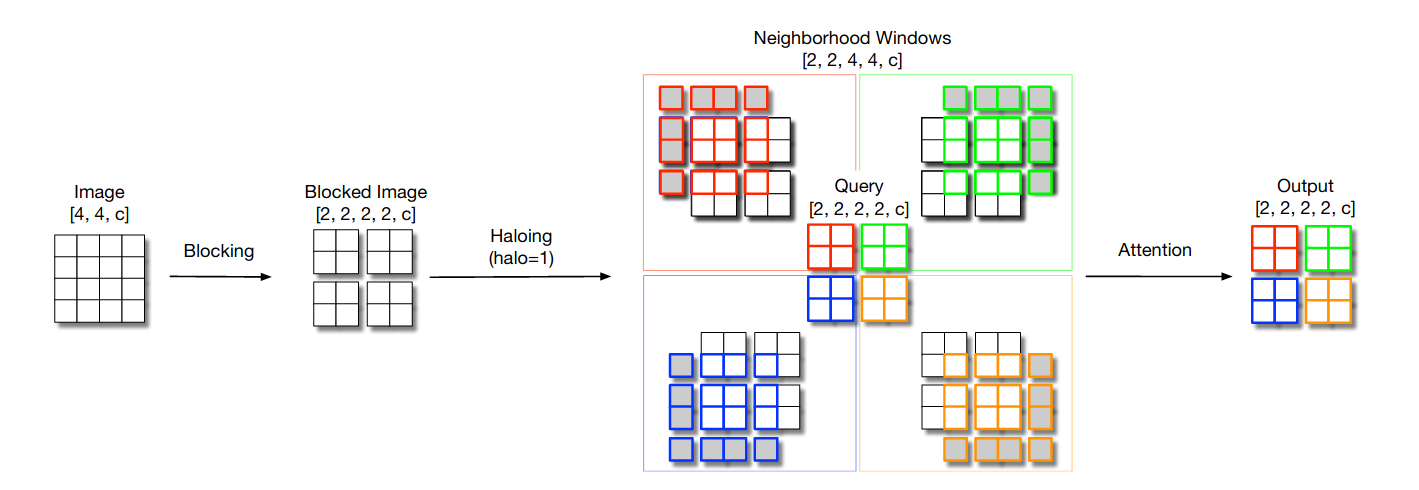
Figure 15: Blocked local Self-Attention as used in HaloNets.
It’s worth noting that this operation causes layers not to be translationally equivariant, but the authors took this route to obtain higher hardware utilization.
The network assumes a hierarchical structure thanks to a strided version of self-attention that is applied at the end of every stage (thus replacing SASA models post-attention average pooling).
The resulting models, called HaloNets, achieved extremely high parameter efficiency, slightly surpassing EfficientNets, a feat not obtained by any other model thus far. It’s worth, however, noting that HaloNets have a longer step-time, particularly when using larger configurations.
Second-order pooling
So-ViT: Mind Visual Tokens for Vision Transformer58 recently proposed the use of second-order pooling to extract high-level information from visual tokens (that is all tokens apart from the class one). The model’s logits are finally obtained by summing up the output of two separate linear heads, one applied to the class token, and one applied to the pooled features.
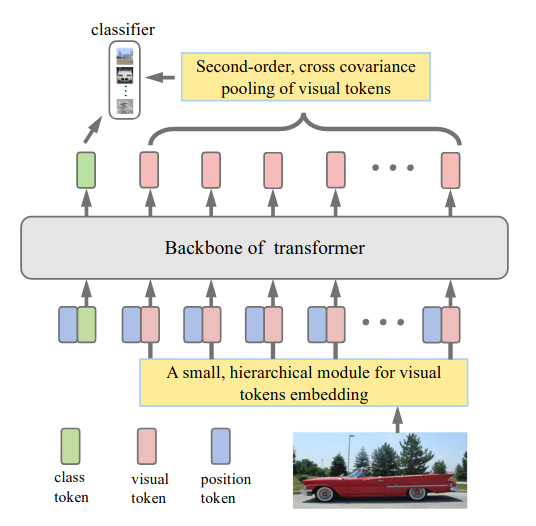
Figure 16: The So-ViT architecture.
The resulting models, named Second-order ViTs (So-ViTs), are trained with an expanded DeiT recipe, and obtain competitive results.
A Comparison for Image Classification
Before continuing, we recap the reported performance of most models presented up to this point.
To provide a fair comparison, we only consider models trained at the same resolution (\(224 \times 224\)) apart from ViTs that were trained at \(384 \times 384\). We also denote models fine-tuned at higher (\(384\times384\)) resolution with an upward arrow, and exclude models trained for more than \(400\) epochs or using the DeiT hard-label distillation technique, because only the DeiT, T2T, and CaiT papers report results using it. Some convolutional models (EfficientNets, NFNets, ResNet-RS and EfficientNetV2s) are included for reference, even though they use both different recipes and training resolution.
We follow An Analysis of Deep Neural Network Models for Practical Applications59 in graphing ImageNet top-1 accuracy vs. FLOPs and parameter count. A lot of models are displayed, so make sure to enable and disable the display of the various models (by clicking them in the legend) as to better explore the visualization.
It’s worth keeping in mind that FLOP use and parameter count are not necessarily representative of latency or memory consumption.
As the recent ResNet-RS paper60 explains, “in custom hardware architectures (e.g. TPUs and GPUs), operations are often bounded by memory access costs and have different levels of optimization on modern matrix multiplication units.” For these reasons, FLOPs are a particularly poor proxy for latency time.
Similarly, the number of parameters is a poor indicator of memory consumption during training. Again from the ResNet-RS paper, “parameter count does not necessarily dictate memory consumption during training because memory is often dominated by the size of the activations” which have to be stored to execute the backpropagation algorithm. “At inference, activations can be discarded and parameter count is a better proxy for actual memory consumption.”
ResNet-RS models are a great example of this issue: an ResNet-RS has respectively \(3{-}4\times\) and \(2\times\) the amount of parameters and FLOPs of a similarly accurate EfficientNet, yet it is \(3\times\) as fast and consumes about \(2\times\) less memory. For these reasons, it would be preferable for authors of new studies to include, together with parameter count and FLOP use, also latency and memory usage measurements.
Robustness and Equivariance
Understanding Robustness of Transformers for Image Classification61 studied the robustness of Vision Transformers to input, model, and adversarial perturbations. The authors found Vision Transformers to have an advantage compared to CNNs of similar size for both input and model perturbations (particularly in large data regimes). However, for some kinds of adversarial attacks, Vision Transformers were found to be more susceptible, at least for small sample sizes.
The authors also found vanilla Vision Transformers highly redundant, a finding first reported in DeepViTs, suggesting the possible use of heavy pruning as a path to more efficient models.
In Group Equivariant Stand-Alone Self-Attention For Vision62, the authors developed a self-attention formulation equivariant to arbitrary symmetry groups. The resulting models, called Group Self-Attention Networks (GSA-Nets), enjoy superior parameter efficiency, although not quite reaching that of comparable-size equivariant CNNs.
Vision Transformers in Self-Supervised Learning
Building on top of previous studies (iGPT63 and masked patch prediction in the Vision Transformers paper19), two papers have investigated self-supervised approaches using Vision Transformers.
An Empirical Study of Training Self-Supervised Vision Transformers64 identified an instability encountered during self-supervised training, causing performance degradation, particularly at large batch sizes. The authors propose a curious trick: a fixed, random patch projection, unlike normal ViTs where patch embeddings are learned just like the rest of the network.
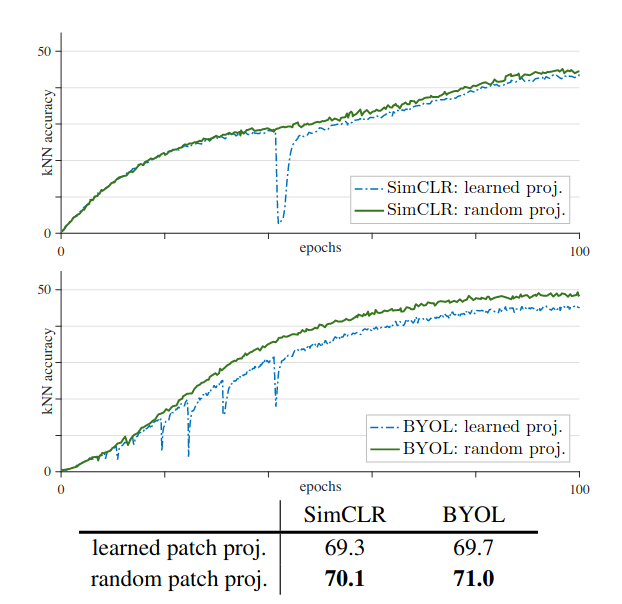
Figure 17: A comparison of training stability using learned and random patch embeddings.
The authors showed that, by coupling this trick with the use of batch normalization in MLP blocks (instead of Layer Normalization), self-supervised training of Vision Transformers could be made more stable, allowing the models to achieve superior performance on several downstream tasks.
Unfortunately, the authors also noted that this approach was not sufficient: the instability is alleviated but not solved, particularly at large learning rates.
SiT: Self-supervised vIsion Transformer65, studied a mix of three semi-supervised tasks (rotation prediction, image reconstruction, and a contrastive one) that, when combined, allow Vision Transformers to perform well on downstream tasks.
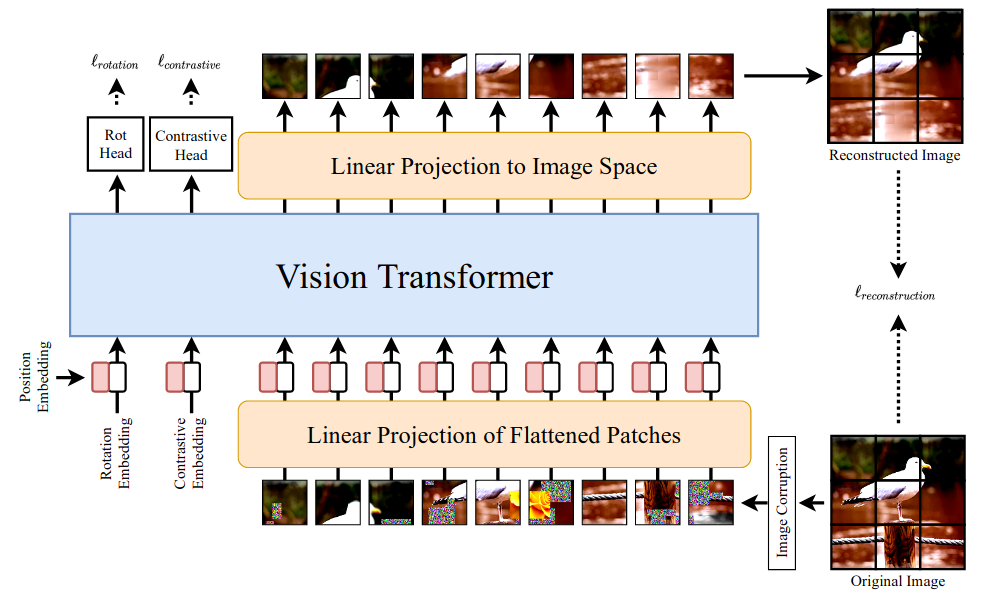
Figure 18: The Self-supervised vIsion Transformer architecture.
Vision Transformers in Medical Research
Vision Transformers have recently been applied to medical research, mainly in segmentation tasks and diagnosis prediction ones.
TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation66 explored using a hybrid CNN-ViT encoder in an UNet-style architecture they call TransUNet. The authors reported favorable results in several segmentation tasks, especially when using a cascaded upsampler to obtain the final segmentation mask.
In Medical Transformer: Gated Axial-Attention for Medical Image Segmentation67, the authors proposed the use of two branches, a shallower one, operating on the global context of the image, and a deeper one, operating locally on patches. The basic building block used for the model, which they named Medical Transformer (MedT), is (gated) axial self-attention16. The authors obtained improvements over baselines on several medical segmentation tasks.
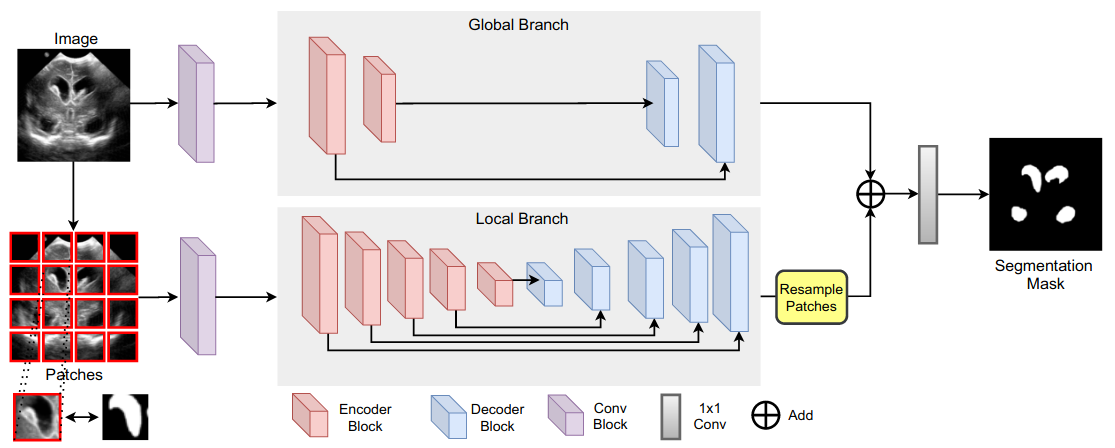
Figure 19: The Medical Transformer architecture.
UNETR: Transformers for 3D Medical Image Segmentation68 adapted ViTs for 3D medical segmentation tasks. The authors showed that a simple adaptation was sufficient to improve over baselines on several 3D segmentation tasks.
Vision Transformers for Video Recognition
Video Transformer Network69 (VTN) proposed the use of a pre-trained 2D spatial backbone (the authors experiment with both CNN-based and ViT-based feature extractors) combined with a Transformer (in this case, a Longformer) operating on the extracted feature maps. The authors showed that this simple approach was competitive with baselines such as SlowFast70.
Is Space-Time Attention All You Need for Video Understanding?71 introduced TimeSformer, an adaption of ViTs to video. After exploring several possible attention variants, the authors proposed one called Divided Space-Time attention. In this approach, frames are first divided into patches and linearly embedded, then fed to a single transformer encoder. Every encoder layer has two attention blocks applied consecutively: the first one on patch embeddings at the same location but in different frames (temporal attention), the second on patch embeddings in the same frame (spatial attention).
The authors adopted ImageNet pretraining for spatial attention blocks and showed that the resulting models achieved state of the art, outperforming previous baselines on standard datasets such as Kinetics-40072.
An Image is Worth 16x16 Words, What is a Video Worth?73 proposed using a Vision Transformer to model the relationship between intra-frame patches, followed by a (temporal) Transformer encoder, modeling inter-frame relationships. It is conceptually similar to a VTN with a ViT-based spatial backbone.
The resulting models (called Spatio and Temporal Transformers, or STAMs) outperformed strong baselines such as X3D74 in the accuracy/FLOPs trade-off.
ViViT: A Video Vision Transformer75 discusses several approaches to adapt ViTs to video, and found the use of tubelet embeddings, linear projections of spatio-temporal tubes, to be most effective.
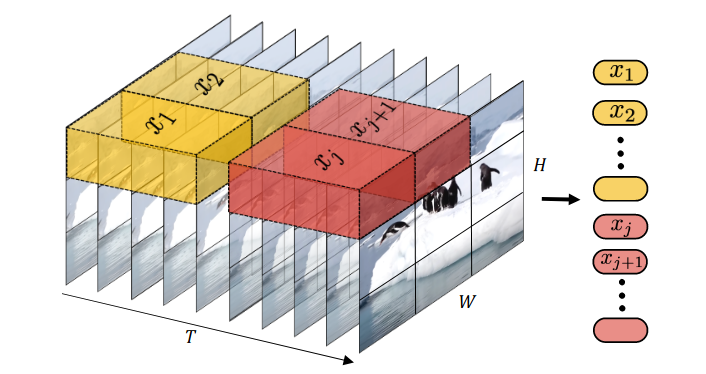
Figure 20: Tubelet embeddings in ViViT.
The positional embeddings are initialized by temporally repeating positional embeddings obtained from pre-trained ViTs. Tubelet embeddings are instead initialized using “central frame initialization”, where the temporally central frame’s embedding is initialized using pre-trained ViT patch embeddings, while the rest are initialized with zeros.
The resulting models, called Video Vision Transformers (ViViTs), achieved state of the art, outperforming TimeSformers, on several standard benchmarks. The authors even reported experiments using an extremely large backbone called ViViT-H, initialized from the similarly large ViT-H pre-trained on JFT-300M. The model obtained a substantial performance improvement, albeit with significant computational cost.
Recently, Multiscale Vision Transformers76 proposed the adoption of a hierarchical structure by progressively increasing the feature dimension while decreasing the spatiotemporal one. This is achieved through the use of pooling, applied to keys and values in attention blocks.
The authors demonstrated the effectiveness of this approach by showing how the resulting models, called Multiscale Vision Transformers (MViTs), could outperform TimeSFormers and ViViTs on standard benchmarks while using a fraction of the compute. Importantly, this method does not require additional data (unlike TimeSFormers and ViViTs, that required ImageNet pretraining).
Conclusion
At the time of writing, the only convolutional architecture still unsurpassed by transformers in efficiency is the recent EfficientNetV2 family of models77, obtained through extensive neural architecture search. No similarly extensive search has been performed for ViT-based models, but the small one reported in CvT: Introducing Convolutions to Vision Transformers53 achieved promising results (CvT-13-NAS).
From recent research, we can draw several conclusions:
- Inductive biases shape a model’s performance. The hard inductive biases that characterize convolutional neural networks provide them with a higher performance floor and a lower performance ceiling. Conversely, transformer-based approaches struggle to compete in the small data regime (thus requiring stronger data augmentations) but shine in regimes where data is plentiful. As many papers investigate, an effective solution may be injecting soft inductive biases in transformers, achieving both high sample efficiency in small data regimes and high model expressiveness when sufficient data is provided.
- Vanilla Vision Transformers appear highly redundant; be it through custom normalization strategies, hierarchical structure, or pruning, they can be made more computationally efficient at little or no performance cost.
- Several studies have highlighted issues with the use of the class token in vanilla Vision Transformers. Better alternatives appear to be both late stage insertion of the class token and the use of global average pooling. Second-order pooling and class-attention layers seem to be better still.
- The amount of research coming out on a daily basis is significant. For this reason, we would like to highlight a few models for a more in-depth look, including the original Vision Transformers19, DeiTs20, TNTs32, ConViTs40, Swin Transformers48, CvTs53, CaiTs35, and ViLs55.
- Transformers in vision are just getting started, and their performance is likely to continue improving as a wider part of the computer vision community adopts them. Increases in compute and data availability are also likely to increasingly tilt the balance in their favor.
The success of transformers in vision has had far-reaching consequences. We have discussed their influence on medical and video tasks, but their impact goes as far as audio (with AST78, Keyword Transformer79) and multimodal architectures (such as ViLT80 and VATT81). Their success has also inspired architectures with even fewer inductive biases, such as the Perceiver82.
One cannot help but feel excited as more and more researchers from all over the artificial intelligence field converge toward common, more general architectures.
Acknowledgements
Thanks to Simone Scardapane, Andrea Panizza, Amedeo Buonanno and Iacopo Poli for help in proofreading and improving this work.